
Video retargeting

Recent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a single pair of 3D source face and target style mesh. The network achieves stylization of the 3D face to the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) to take as input a mesh of diverse topologies to the stylization process by encoding its shapes into our latent space. The resulting stylized face model can be animated by commonly used 3DMM blend shapes. A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and outputs them in a desired topology. We also demonstrate example applications of our method including facial animation of stylized avatars and linear interpolation of geometric styles.





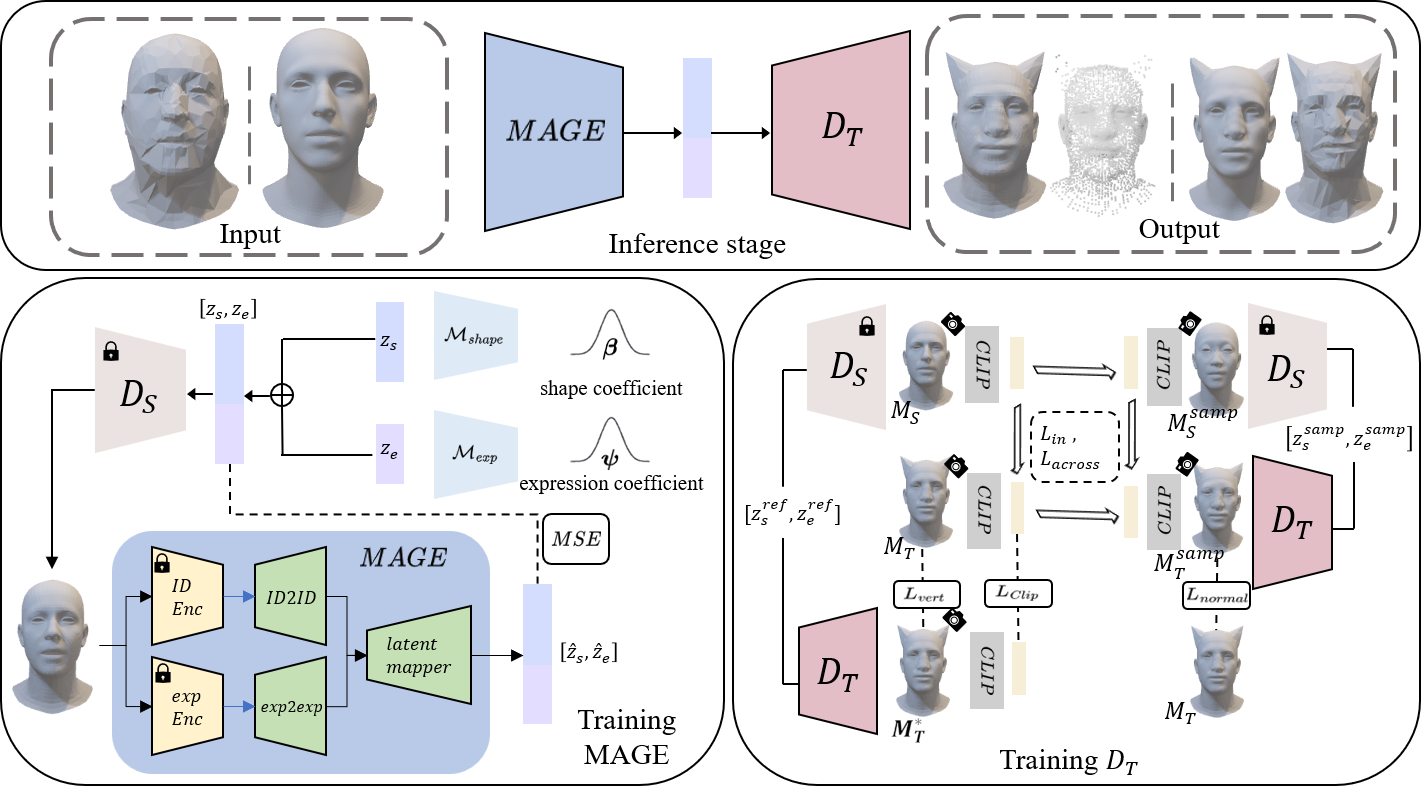
Overview of LeGO: The upper box illustrates the inference stage, where our method takes diverse input meshes and generates stylized outputs. In the lower-left box, the training process of Mesh Agnostic Encoder (MAGE) is depicted. In the lower-right box, the fine-tuning process of $D_T$ is illustrated.